
Acoustical Models that Make Sense
by Richard Honeycutt
In this article, Richard Honeycutt compares predictions of four different modeling programs. The results were surprising.
While preparing a series of columns on acoustical modeling software for AudioXpress Magazine (April, May, June, and July 2014 issues), I was reminded of something we all should know, but may need to occasionally be reminded of: the predictions of modeling software can be like measurements using uncalibrated instruments. I built a model and ran it in four full acoustical modeling programs. The model was built in one of the programs, then exported to DXF, in which form it was imported into the other programs. Thus the four models, including the material absorption properties, were for all practical purposes identical. The only variation is that the modeling of the audience area was adjusted to conform to the method recommended by the developer of each software package. (More details in a future blog.)
I was not surprised to find differences in the predictions by different modeling programs, since they all use different algorithms, and some include diffraction effects; whereas, others do not. What did surprise me was the extent of the variations. As you can see from Figure 1, the variation in predictions is certainly not insignificant. In addition to the RT predicted by the full analysis algorithm of programs A, B, C, and D, I have included predictions using statistical methods by Sabine, Eyring, and Puchades. It is no surprise that the statistical predictions disagree, since the room I modeled does not meet the criteria for accurate statistical prediction. I was, however, very surprised to find that the Eyring prediction from one modeling program (designated “A”) agreed closely with the Sabine prediction; whereas, in another program (“B”), it did not.
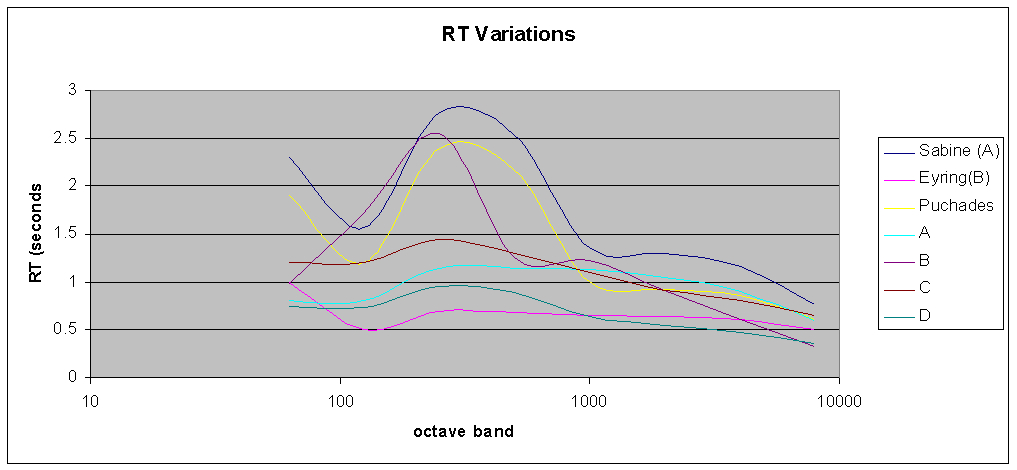 Figure 1: Variations in predicted RT among respected modeling programs.
Figure 1: Variations in predicted RT among respected modeling programs.
The point is not to compare the accuracy of the various programs; doing that would have required that each model be built by an expert in using the particular software, but all working from the same room dimensions and materials. So this is not about a “shootout”. The vital point is that, since there are differences among the outcomes from several very good programs, and the variability may be due to the models I built, the analytical algorithms, or probably both. It is essential that whenever possible, we validate our models with actual measurement results. This is easy to do in a room that is scheduled for renovation: when we are on site to gather information, we make RT measurements at several points in the room at the same time. If intelligibility is known to be a problem in the room, we should make STI measurements as well. And if there are known echo problems, we should spend the time to locate the worst reflecting surfaces. Then once we have built the model, we can see if its predictions match our measurements. If not, we may have to tweak our material absorption values, which are all approximate, anyway.
For new-construction projects, we must wait until the project is complete to make our measurements. So although the measurements may not assist us on that particular project, they can serve as a sort of “modeling calibration” test of our overall modeling practices.
Several round robin tests of modeling software have been conducted, and these generally indicate that most of the well-known full modeling programs are pretty good. (I say “most of” because not all developers have participated in the round robin tests.) But bear in mind that there may be some consultants and contractors—you and I may be among them—who are not as expert at modeling as the developers themselves are, and/or there may be some material absorption databases that are not as accurate or as applicable to our projects, as we think they are.
- Bottom line: just as we are fooling ourselves if we rely on uncalibrated test and measuring equipment, we may also be fooling ourselves if we don’t spend the time to calibrate poor modeling practices. rh
 Richard A. Honeycutt developed an interest in acoustics and electronics while in elementary school. He assisted with film projection, PA system operation, and audio recording throughout middle and high school. He has been an active holder of the First Class Commercial FCC Radiotelephone license since 1969, and graduated with a BS in Physics from Wake Forest University in 1970, after serving as Student Engineer and Student Station Manager at 50-kW WFDD-FM. His career includes writing engineering and maintenance documents for the Bell Telephone System, operating a loudspeaker manufacture company, teaching Electronics Engineering Technology at the college level, designing and installing audio and video systems, and consulting in acoustics and audio/video design. He earned his Ph.D. in Electroacoustics from the Union Institute in 2004. He is known worldwide as a writer on electronics, acoustics, and philosophy. His two most recent books are Acoustics in Performance and The State of Hollow-State Audio, both published by Elektor.
Richard A. Honeycutt developed an interest in acoustics and electronics while in elementary school. He assisted with film projection, PA system operation, and audio recording throughout middle and high school. He has been an active holder of the First Class Commercial FCC Radiotelephone license since 1969, and graduated with a BS in Physics from Wake Forest University in 1970, after serving as Student Engineer and Student Station Manager at 50-kW WFDD-FM. His career includes writing engineering and maintenance documents for the Bell Telephone System, operating a loudspeaker manufacture company, teaching Electronics Engineering Technology at the college level, designing and installing audio and video systems, and consulting in acoustics and audio/video design. He earned his Ph.D. in Electroacoustics from the Union Institute in 2004. He is known worldwide as a writer on electronics, acoustics, and philosophy. His two most recent books are Acoustics in Performance and The State of Hollow-State Audio, both published by Elektor.